Let’s see how we can compose that particular model, step by step. Probably sQUlearn is one of the best resources in order to simplify our code. We will start loading the data. The infamous iris datatset (we will only take the first two values).
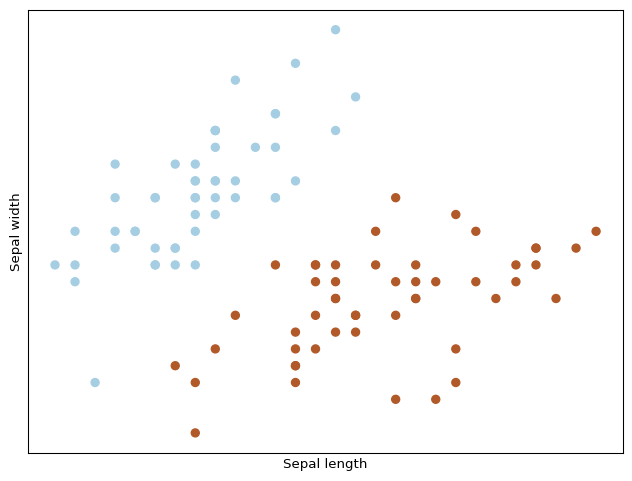
import matplotlib.pyplot as pltfrom mpl_toolkits.mplot3d import Axes3Dfrom sklearn import datasetsfrom sklearn.decomposition import PCA# import some data to play withiris = datasets.load_iris()X = iris.data[:100, :2] # we only take the first two features.Y = iris.target[:100] # and first 100 samplesplt.figure(2, figsize=(8, 6))plt.clf()# Plot the training pointsplt.scatter(X[:, 0], X[:, 1], c=Y, cmap=plt.cm.Paired)plt.xlabel('Sepal length')plt.ylabel('Sepal width')plt.xticks(())plt.yticks(())plt.show()
The task here is to find a good projection of those features so that we can better separate between the three classes (Setosa, Virginica and Versicolor). Some key steps are the splitting so that we have a fear metric to evaluate and the scaling of the variables.
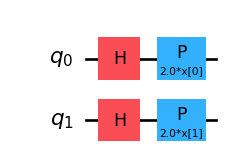
Now we need to select a good embedding… Well, let try with a simple Z feature map.
from qiskit.circuit.library import ZFeatureMapfmap = ZFeatureMap(X_train.shape[1], reps=1)fmap.decompose().draw('mpl')
Now we know where we will put our data. We need to compose a kernel with that. The simplest one,
from qiskit_machine_learning.kernels import FidelityQuantumKernelfrom qiskit_algorithms.state_fidelities import ComputeUncomputefrom qiskit.primitives import Sampler# How to compute the fidelity between the states fidelity = ComputeUncompute(sampler=Sampler())# Feature map and quantum Kernelkernel = FidelityQuantumKernel(feature_map=fmap, fidelity=fidelity)kernel.evaluate(X_train[0,:], X_train[0,:])
array([[1.]])
That makes sense, a complete overlap between the two. What happens if we use different sample points.
\[
TA(K) = \frac{\sum_{ij}K(x_i,x_j)y_iy_j}{\sqrt{\sum_{ij}K(x_i,x_j)^2\sum_{ij}y_i^2y_j^2}}
\] where \(K\) is our kernel. We can test how good our kernel is then.
import numpy as npdef target_alignment(kernel, X, y_labels) ->float:# Get estimated kernel matrix kmatrix = kernel.evaluate(X)# Scale y values to -1 and 1 nun_plus = np.count_nonzero(np.array(y_labels) ==1) num_minus =len(y_labels) - nun_plus _Y = np.array([y / nun_plus if y ==1else y / num_minus for y in y_labels]) T = np.outer(_Y, _Y) # Y outer product numerator = np.sum(kmatrix * T) denominator = np.sqrt(np.sum(kmatrix * kmatrix) * np.sum(T * T))return numerator / denominatortarget_alignment(kernel, X_train, y_train)
np.float64(0.6075420371223076)
target_alignment(kernel, X_test, y_test)
np.float64(0.5026116721148101)
Not bat, we could then get an estimate on the separability of a selected kernel with this. Now that we know our kernel is good enough, lt’s check how it works alongside a Support Vector Classifier.
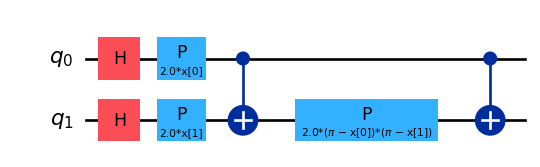
We can try with a little bit more complex feature map. In fact, \(Z\)-embedding has no entanglement capacity as it is only composed by independent single qubit rotations. We can add a little bit of entanglement to it and check if that performs better (it has entanglement and that is cool, so it should work better).
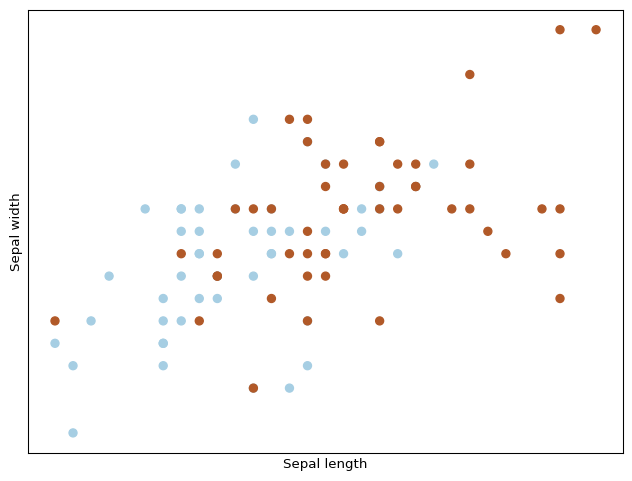
# import some data to play withiris = datasets.load_iris()X = iris.data[50:150, :2] # we only take the last two features.Y = iris.target[50:] # and first 100 samplesplt.figure(2, figsize=(8, 6))plt.clf()# Plot the training pointsplt.scatter(X[:, 0], X[:, 1], c=Y, cmap=plt.cm.Paired)plt.xlabel('Sepal length')plt.ylabel('Sepal width')plt.xticks(())plt.yticks(())plt.show()
That looks more complex. Let’s check our previous feature map.
We can see how well the representation in the bloch sphere separates the two groups.
target_alignment(kernel, X_train, y_train)
np.float64(0.843602003610384)
target_alignment(kernel, X_test, y_test)
np.float64(0.7336524493034711)
Curious enough, the \(TA\) is higher in this case, meaning it separates better between the two groups, yet the classificaiton is worst. Let’s check out with some more complex feature map.
from qiskit.circuit.library import ZZFeatureMap# Feature map and kernel compositionfmap = ZZFeatureMap(X_train.shape[1], reps=1)fmap.decompose().draw('mpl')
Well, the \(TA\) in this case shows it separates worst in the latent Hilbert space data is encoded into so it might make sense that this worsens the prediction. But common, we added entanglement, that is the magic sauce for QML. That should do it’s thing right? Well, I guess this is why people has not yet solved why and how QC will boost ML for the general case.
Hubregtsen, Thomas, David Wierichs, Elies Gil-Fuster, Peter-Jan H. S. Derks, Paul K. Faehrmann, and Johannes Jakob Meyer. 2022. “Training Quantum Embedding Kernels on Near-Term Quantum Computers.”Physical Review A 106 (4). https://doi.org/10.1103/physreva.106.042431.