At some point, other than scheduling tasks you may need to orchestrate some complex workflows. It often requires setting up complex architectures and thinking about the potential needs. It gets serious and there are pretty good options out there in the open-source ecosystem so that you don’t need either to deploy the most complex thing in the world or pay a tone of money to get professional orchestration.
Hopefully this list will help you get started focusing on what you might need and select the right tool for you.
Simple yet powerful
In many cases the need comes from the fact that Python is a single process slow language. Leveraging multiprocessing techniques does not guaranty complex workflows take into consideration where it failed during the last run and reattempt the whole thing.
redun is one of those simple but useful examples. Follows some of the common practices when it comes to task scheduling, simple function annotation and you are good to go.
# hello_world.py
from redun import task, Scheduler
redun_namespace = "hello_world"
@task()
def get_planet():
return "World"
@task()
def greeter(greet: str, thing: str):
return "{}, {}!".format(greet, thing)
@task()
def main(greet: str="Hello"):
return greeter(greet, get_planet())
if __name__ == "__main__":
scheduler = Scheduler()
result = scheduler.run(main())
print(result)Its lazy evaluation, caching mechanism and parallelism makes any Python program scale to exploit all resources available in the machine. The executors allow for a fully detached architecture.
Recommended
For simple projects or self-contained projects that might require internal orchestration as part of their process, in particular if task duplicity exists as it may decrease significantly the amount of computation needed (think of evolutionary algorithms for example).
Mission critical
Some orchestrations must guarantee execution and delivery of the workflow. Temporal is a workflow orchestration platform designed for reliability and scalability in mission-critical applications. It enables developers to define workflows as code, handling state, retries, and error recovery automatically. Temporal supports long-running workflows, distributed execution, and guarantees workflow completion even in the face of failures. Its architecture decouples workflow logic from infrastructure concerns, making it suitable for complex business processes and microservices orchestration.
@workflow.defn
class SleepForDaysWorkflow:
# Send an email every 30 days, for the year
@workflow.run
async def run(self) -> None:
for i in range(12):
# Activities have built-in support for timeouts and retries!
await workflow.execute_activity(
send_email,
start_to_close_timeout=timedelta(seconds=10),
)
# Sleep for 30 days (yes, really)!
await workflow.sleep(timedelta(days=30))Recommended
If you are thinking on a production workflow, operational excellence, this might be the best option for you. Transaction management will be a key benefit in this particular case.
Pythonic DAGs
Airflow is probably the best known solution for general case workflows. It can integrate with almost anything, it can scale due to its decoupled architecture,… But being around for a while guarantees some room from improvement on early day decisions and come competitors took advantage on those.
from datetime import datetime
from airflow.sdk import DAG, task
from airflow.providers.standard.operators.bash import BashOperator
# A DAG represents a workflow, a collection of tasks
with DAG(dag_id="demo", start_date=datetime(2022, 1, 1), schedule="0 0 * * *") as dag:
# Tasks are represented as operators
hello = BashOperator(task_id="hello", bash_command="echo hello")
@task()
def airflow():
print("airflow")
# Set dependencies between tasks
hello >> airflow()While Airflow is widely adopted, it has some limitations that motivated the creation of newer tools like Prefect and Dagster:
- Complexity in DAG authoring: Airflow DAGs are defined as Python scripts, but the execution model is not fully Pythonic. Dynamic workflows and parameterization can be cumbersome.
- State management: Airflow relies heavily on external databases for tracking state, which can lead to synchronization issues and operational overhead.
- Testing and local development: Testing Airflow workflows locally is challenging due to its dependence on a running scheduler and metadata database.
- Error handling and retries: Error handling is less flexible, and retry logic is not as granular or intuitive as in newer frameworks.
- Extensibility and modularity: Airflow’s plugin system and operator model can be limiting for building reusable, composable workflows.
Prefect and Dagster were designed to address these pain points by offering more Pythonic APIs, improved state management, better local testing, and enhanced observability.
Prefect
Prefect is a modern workflow orchestration tool designed for simplicity, reliability, and scalability. It allows you to define, schedule, and monitor data workflows using Python code, with built-in support for retries, caching, and observability.
from prefect import flow, task
@task
def get_planet():
return "World"
@task
def greeter(greet: str, thing: str):
return f"{greet}, {thing}!"
@flow
def main(greet: str = "Hello"):
planet = get_planet()
message = greeter(greet, planet)
print(message)
if __name__ == "__main__":
main()Dagster
Dagster is a modern data orchestrator focused on reliability, modularity, and observability. It lets you define workflows as Python code, with strong typing, testing, and monitoring support.
from dagster import job, op
@op
def get_planet():
return "World"
@op
def greeter(greet: str, thing: str):
return f"{greet}, {thing}!"
@job
def main():
message = greeter("Hello", get_planet())
print(message)
if __name__ == "__main__":
main.execute_in_process()Recommended
Previous options are suitable, might prefer the modern options if you are willing to risk some interoperability as they may enable better pipeline testing functionalities.
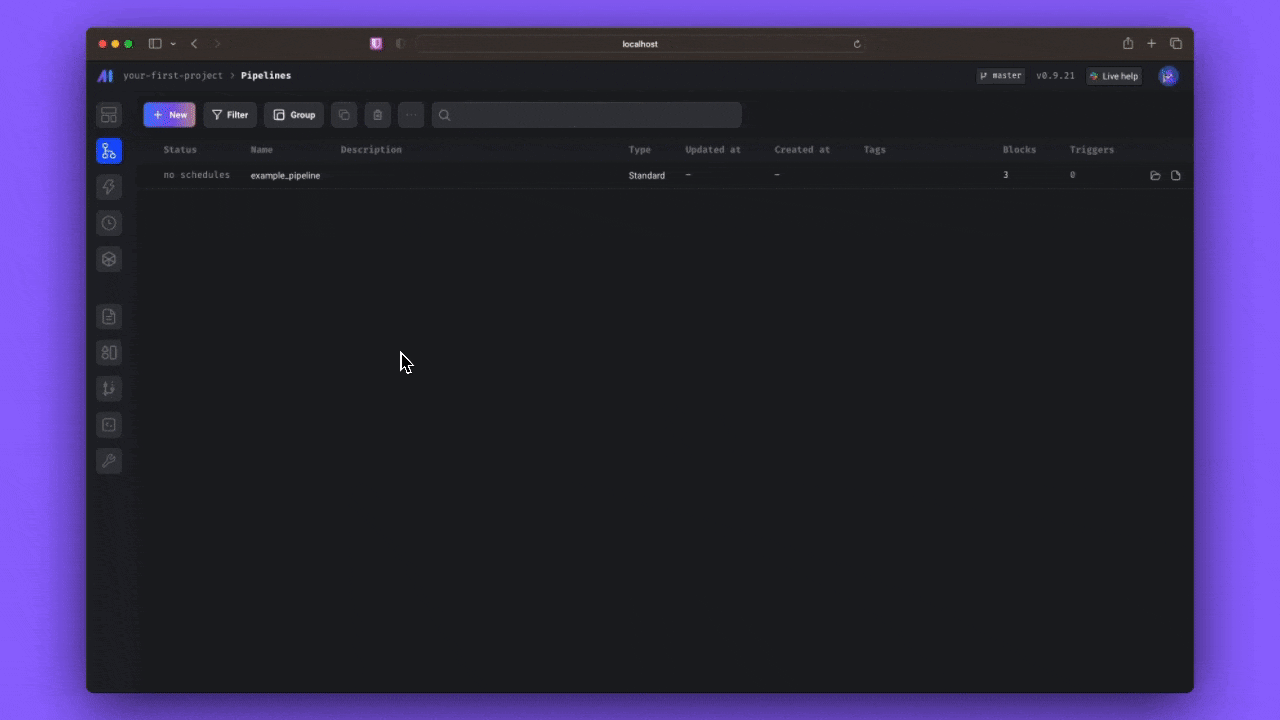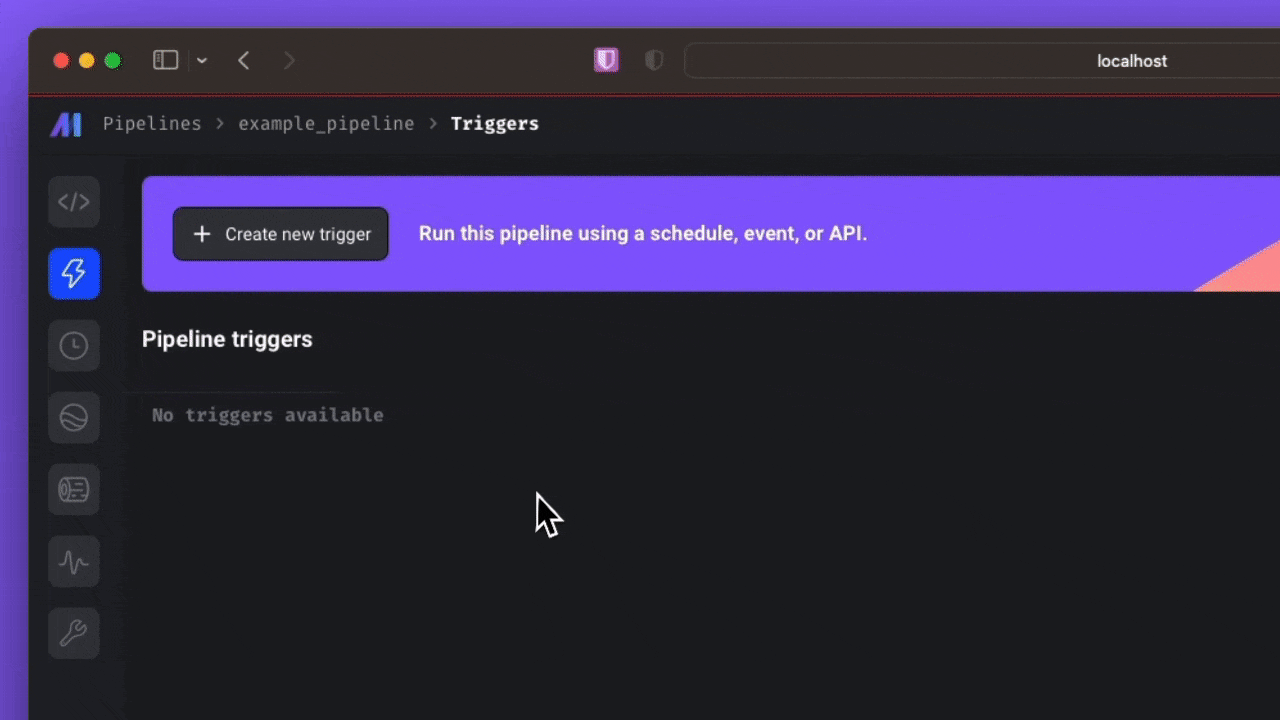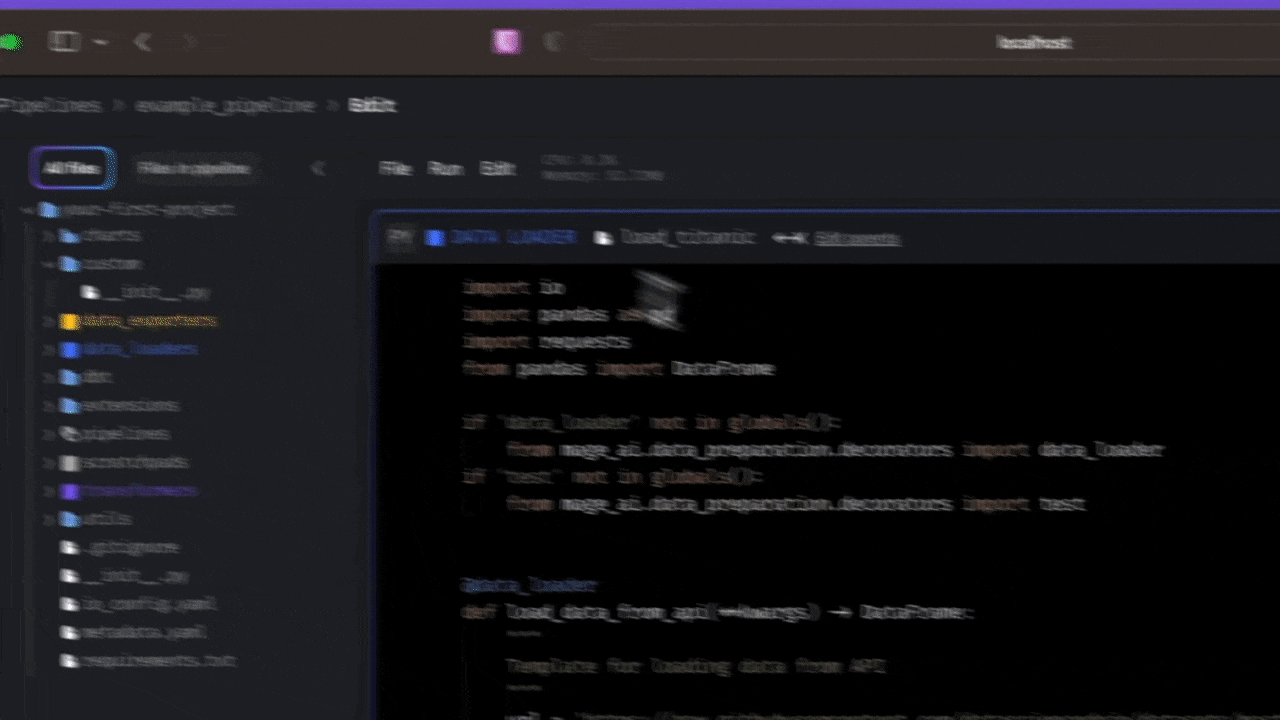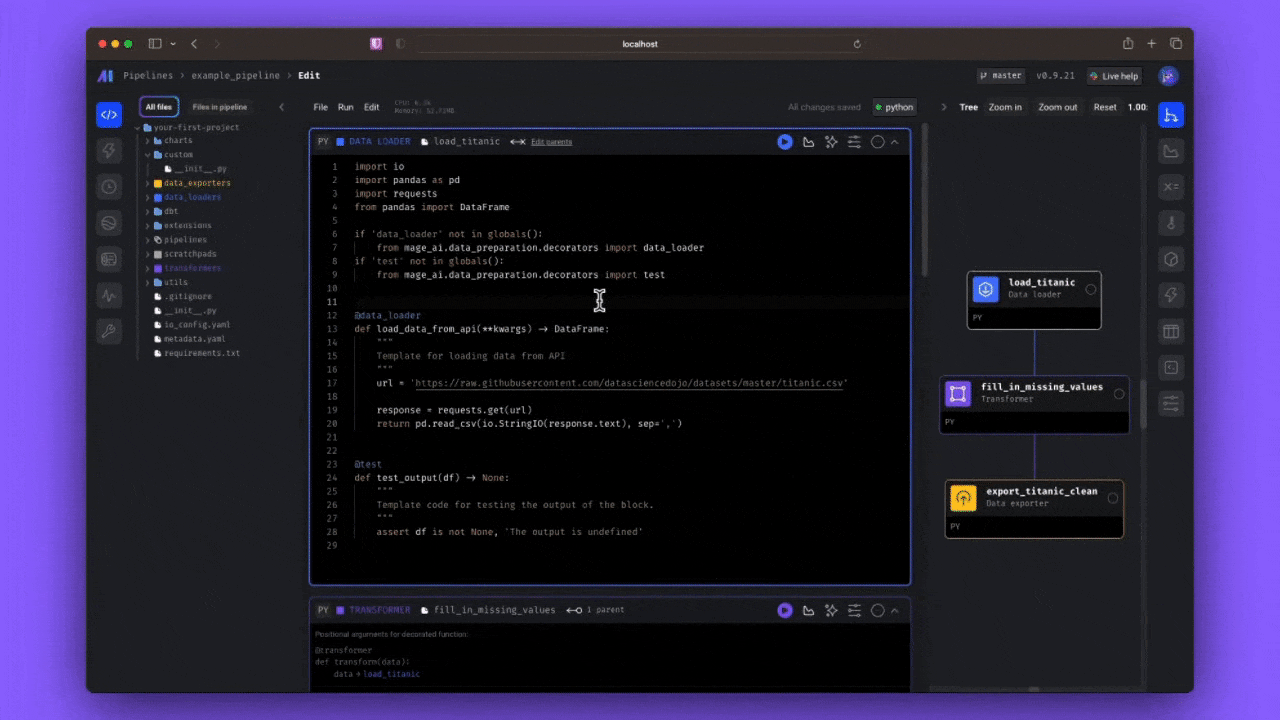
Mage
Mage despite being yet another alternative to Airflow, Prefect and Dagster and once again prioritize code-defined DAGs, its webserver presents as an edite, really close to Notebook. This make is much easier to be adopted by Data Science teams even though offers the same functionalities and code reusability other orchestration tools offer.
A similar option, not tested yet is Orchestra even though it may lack the visual editor functionality I like so much about Mage.
Recommended
Make sure you try this one if your Data Scientists are open to adopt an orchestration tool. This may be the best option to have them onboard and yet have a professional orchestration for those messy notebooks you are handed over every once in a while.
Containers please
Some solutions have focused on containerized execution enabling a broader range or, better said, a different set of orchestration use cases.
Dagger is a programmable CI/CD engine that lets you define workflows using familiar programming languages, focusing on containerized tasks. Dagger enables you to build, test, and deploy applications in isolated environments, ensuring reproducibility and portability.
Dagger can help manage containers and locally emulate your CI/CD pipelines with any of the coding options it provides (Go, Python, Java, TypeScript):
import dagger
from dagger import dag, function, object_type
@object_type
class MyModule:
@function
def build(self, src: dagger.Directory, arch: str, os: str) -> dagger.Container:
return (
dag.container()
.from_("golang:1.21")
.with_mounted_directory("/src", src)
.with_workdir("/src")
.with_env_variable("GOARCH", arch)
.with_env_variable("GOOS", os)
.with_env_variable("CGO_ENABLED", "0")
.with_exec(["go", "build", "-o", "build/"])
)As an alternative, Kestra is a modern, scalable orchestration platform designed for data workflows and automation. It features a YAML-based workflow definition, a powerful web UI, and native integrations with cloud services, databases, and messaging systems. Kestra supports event-driven and scheduled workflows, making it suitable for both batch and real-time data processing.
A simple Kestra workflow example in YAML would look like
id: getting_started
namespace: company.team
tasks:
- id: hello_world
type: io.kestra.plugin.core.log.Log
message: Hello World!Recommended
Testing any CI/CD locally and making sure the automation happens as you want it to, really independent of the machine.
Other options
Orchestration and task scheduling is a must in most projects, and those little discrepancies between tools really matter as they better fit specific use cases.
Apache Hop
Apache Hop is a full-fledge suite for pipeline and workflow management. Java based, looks old-school even though its execution engines (Apache Spark, Apache Flink or Apache Beam) guaranty its performance is top notch.
Apache Nifi
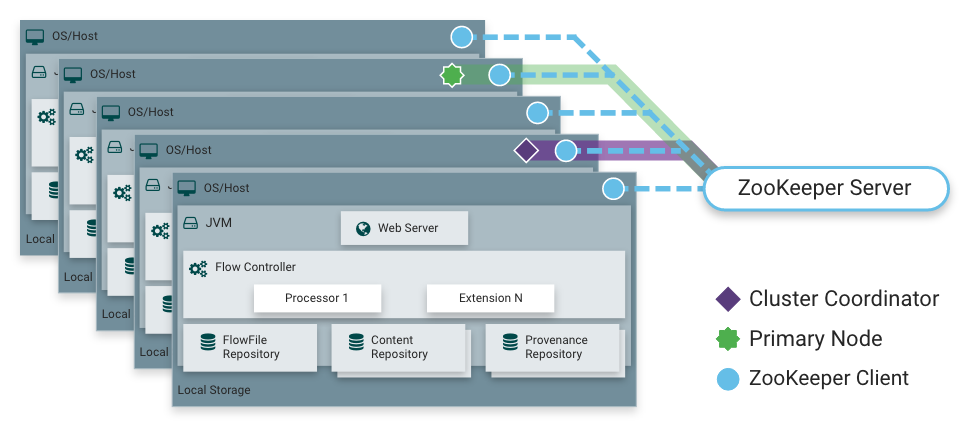
Thought for the real-time era, Apache Nifi was released as part of the NSA’s technology transfer program in 2014. Its GUI is simple yet powerful. More so its distributed execution architecture.
dbt
dbt even though it could fit in a completely different category we can see it as a SQL or transformation orchestration tool It follows some of the premises of previous modern orchestration tools being code-first, git-native and extensible. With its acquisition of SDF and improved Fusion engine some pretty cool functionalities have been added.
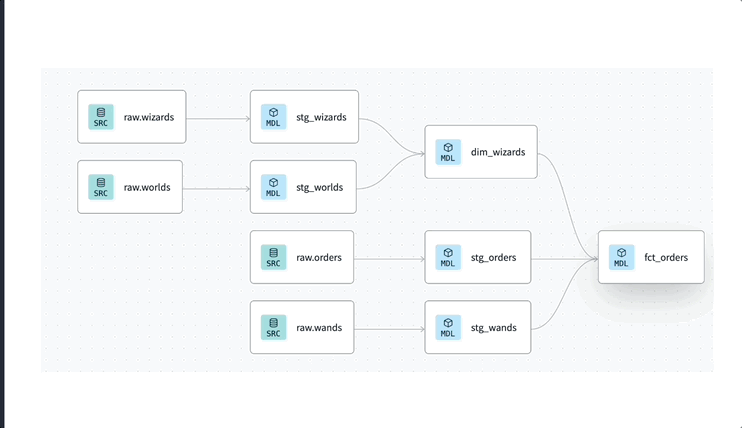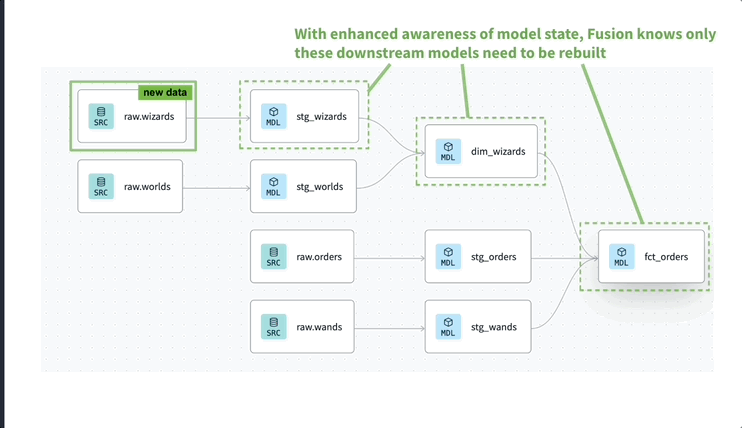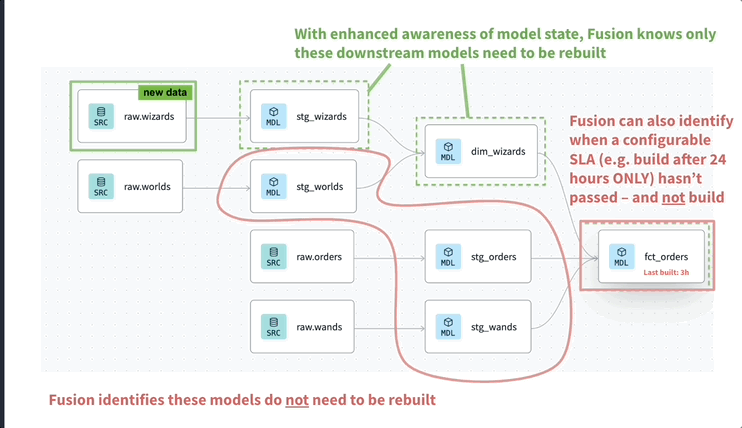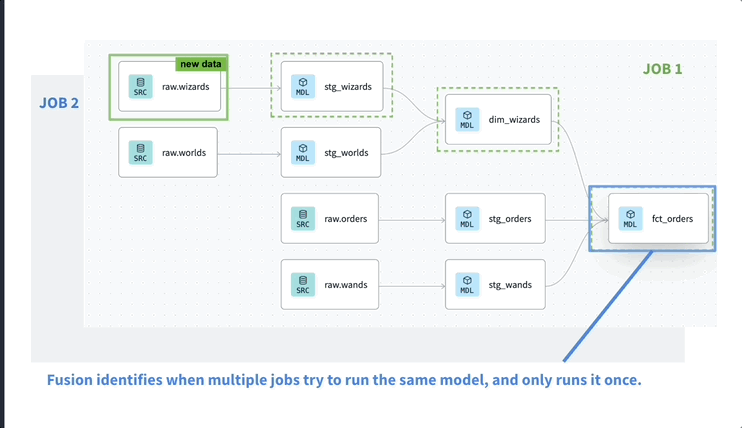
Even though, my gut tells me the less known SQLMesh may dethrone dbt in the coming years.
Celery
Celery is more a task queue management, therefore task handover and execution is managed by the framework while other features such as task reattempts and result caching might be as straightforward to handle in comparison with other options.
from celery import Celery
app = Celery('hello', broker='amqp://guest@localhost//')
@app.task
def hello():
return 'hello world'We won’t extend the task scheduling or distributed computing orchestration as this would require a huge post, but consider some frameworks such as Apache Spark or Ray also have part of this ability in them.